The internals¶
3 main differences¶
Let’s start with three git’s features you should become familiar with.
- There’s no server: the repository is local. Most operations are local and don’t require network access. Also for this reason you will find git incredibly fast.
- The project is indivisible: git always works with the whole
source code of the project and not on single directories or files;
committing in the main directory or in a sub-directory is exactly the same thuing.
The concept
checkoutof a single file or directory doesn’t exist. git assumes the project as the indivisible unit of work. - git doesn’t memorize files’ changes: git always saves entire files. If you modify a single character of a 2 mega file, git memorizes in full the new version of the file. This is an important difference: SVN memorizes the differences and, when required, rebuilds the file; git memorizes the file and, when required, rebuilds the differences.
4 levels of offline operations¶
Re the absence of a server i lied a little: as I already said and as you will see later, git is a peer-to-peer system, and it can interact with remote servers. Despite this, it remains a substantially local system.
In order to better understand how this can benefit you, try to see what follows: when a project’s source code is hosted on a remote computer, you have four ways to edit the code
- You leave all the code on the remote computer and access it with ssh to edit a single file
- You find the way to obtain a copy of the single file so that you can work on it in local more comfortably, and you leave all the rest on the remote computer
- You find the way to obtain a local copy of a whole file system tree and leave the rest of commits’ history on the remote computer
- You obtain a local copy of the whole repository with the whole history of the project and you work locally.
You may have noticed two things.
First, SVN and other versioning systems you might be used to, operate at level 3.
Second, the 4 systems are listed in order of convenience: in principle, when the material stays on the remote system, your work becomes more intricate, slow and umcomfortable. SVN allows you to checkout a whole directory precisely because in this way you find more comfortable passing from one file to another without need to interact continually with the remote server.
git is even more extreme; it prefers that you have everything at hand on your local computer; not just the single checkout, but the whole history of the project, from first to last commit.
In fact, whatever you want to do, git normally asks for getting a complete copy of what is present on the remote server. But don’t worry too much: git is faster in getting the whole history of the project than SVN is in getting a single checkout.
The storage model¶
Let’s pass now to the third difference. And be prepared to know the true reason why git is very quickly going to substitute SVN as the new de-facto standard
- SVN memorizes the collection of various changes applied to files during time; when required it rebuilds the present state;
- git memorizes files as they are, in full; when required it computes their deltas.
If you want to avoid many headaches with git, the best suggestion you can follow is to treat it as a key/value database.
Now go to your terminal and look in concrete.
Put yourself in the condition to have two empty files on your file system:
mkdir project
cd project
mkdir libs
touch libs/foo.txt
mkdir templates
touch templates/bar.txt
/
├──libs
| └──foo.txt
|
├──templates
└──bar.txt
Let’s decide to manage the project with git
git init
Add the first file to git
git add libs/foo.txt
With this command, git inspects the file content (it’s empty!) and
memorizes it on its key/value database, named Object Database and
stored on the file system in the .git hidden directory.
Since the blob-storage is a key/value database, git will try to
compute a key and a value for the file you have added. For the value it
will use the file content itself; for the key, it will compute the
SHA1 of the content (if you are curious, in case of an empty file it’s
e69de29bb2d1d6434b8b29ae775ad8c2e48c5391)
So, in the Object Database git will save a blob object,
uniquely identifiable by its key (that, in absence of ambiguity, it’s
worth to shorten)
Now add the second file
git add templates/bar.txt
Now, since libs/foo.txt and templates/bar.txt have the same identical
content (they are both empty!), in the Object Database they are going to
be stored both in a single object:
As you can see, in the Object Database git has memorized only the file
content, and not its name or its location.
But of course we are very interested in file names and locations, aren’t we?
For this reason, in the Object Database, git memorizes also other objects,
named trees that serve just to memorize content of the different
directories and file names.
In our case, we will have 3 trees
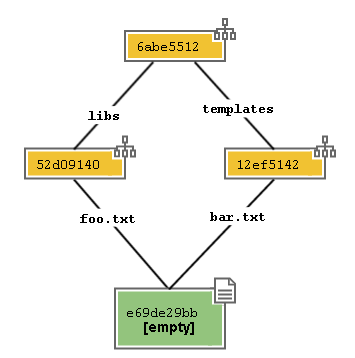
As any other object, also trees are memorized as key/value objects.
All these structures are collected in a container, called commit.
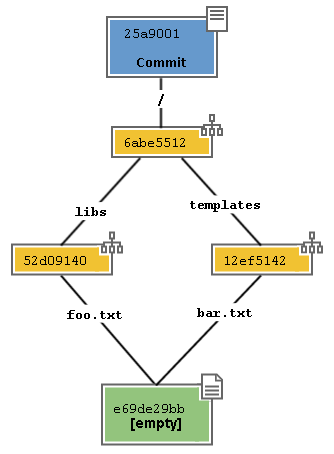
As you have probably guessed, a commit is nothing more than an item
of the key/value database, whose key is a SHA1, as for all
other objects, and whose value is a pointer to the project’s tree ,
that is its key (together with some other information, like creation date,
comment and author). In the end it’s not that much complicated, isn’t it?
So, the commit is the present photography of the file system.
Now type
git commit -m "commit A, my first commit"
You are saying to git:
memorize in the repository, that is in the project’s history, the commit I have prepared by several adds
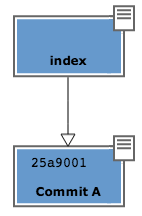
Your repository, seen by SmartGit, has now this aspect:
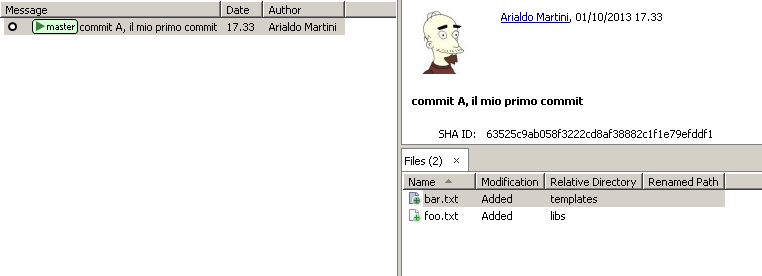
The line with bullet that you see on the left represents the commit
object. In the panel on the right, instead, you may see the commit key.
In general, unless we want to speak precisely of the internals model, as
we are doing now, there’s not a great need to represent the whole structure
of blobs and trees that constitutes a commit. In fact, after
the next paragraph we will start to represent the commit like in the figure
above: with a simple bullet.
Even now, however, for you it should be clearer that inside a commit
there is the whole photography of the project and a commit actually is
the minimal and indivisible unit of work.
The index or staging area¶
Substantially, there’s not much more that you have to know about git’s storage
model. But before we pass to see the various commands, I’d like to introduce
another internal mechanism: the staging area or index. The index` always
results a mystery if one comes from SVN: it's worth to speak about it,
because when you know how ``Object Database and index work, no longer will
git appear to you intricate and incomprehensible; rather, you will get its coherence
and you’ll find it extremely predictable.
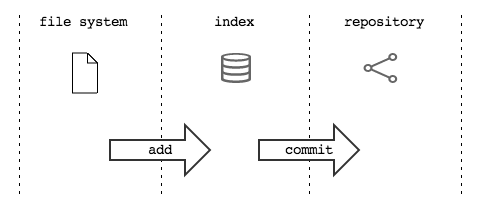
The index is a structure that acts as a pad between file system and
repository. It’s a small buffer you can use tu build your next commit.

It’s not that much complicated:
- the
file systemis the directory with your files - the
repositoryis the local database on file that stores the variouscommits - the
indexis the space that git provides you to create the nextcommit
before recording it definetely on the repository.
Physically, index is not very different from repository:
both store data in the Object Database, using the structures you have
seen above.
At this moment, just after having completed your first commit,
the index stores a copy of your last commit and expects that you
modify it.
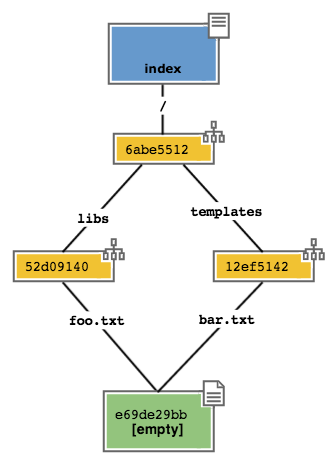
On file system you have
/
├──libs
| └──foo.txt
|
├──templates
└──bar.txt
Let’s try to make some changes to file foo.txt
echo "in the middle of the way" >> libs/foo.txt
and update the index with
git add libs/foo.txt
Here you have another difference from SVN: in SVN add serves to put
a file under versioning and it has to be executed only once; in git it serves
to save a file inside index and it’s an operation that has to be
repeated at every commit.
When you run git add , git repeats what it had already done before:
it analyzes the content of libs/foo.txt, it sees that there’s a content it
has never recorded and therefore it adds to the Object Database a new
blob with the new content of the file; contestually, it updates the tree
libs so that the pointer named``foo.txt`` addresses its new content.
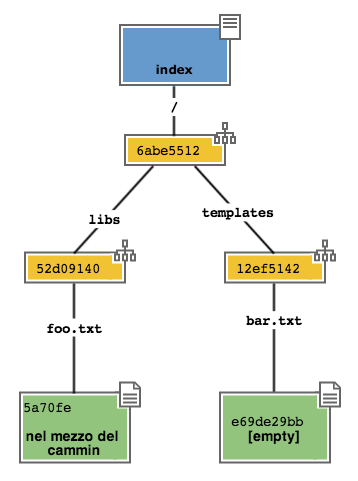
Go on adding a new file doh.html to the project’s root
echo "happy happy joy joy" > doh.html
git add doh.html
Like before: git adds a new blob object with the file’s content and,
contestually, adds in the “/” tree a new pointer named doh.html
that points to the new blob object
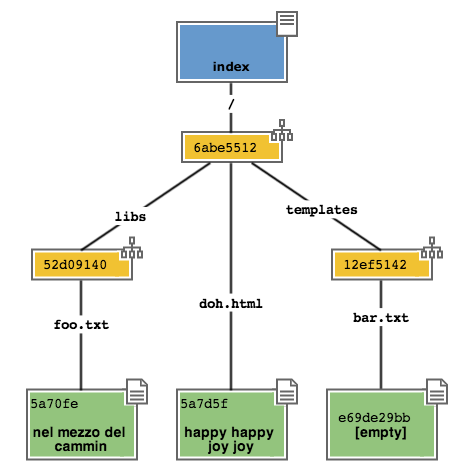
The container of all this structure is always a commit object;
git keeps it parked in the staging area waiting for you to send it to
repository. This structure exactly represents the new situation on
file system: it’s again a photography of the whole project, and it includes
also the bar.txt file, despite you have now modified it. Incidentally:
you shouldn’t worry for space usage because, as you can see, to memorize
bar.txt git is reusing the blob object it created in the previous
commit, in order to avoid duplications.
Well. Now we have a new photography of the project. But we are interested in
git storing also the history of our file system, therefore it’ll be needed
to memorize somewhere the fact that this new situation (the present index
state) is daughter of the previous situation (the previous commit).
In effect, git adds authomatically to the commit parked in the staging
area a pointer to the source commit
The arrow represents the fact that the index is son of commit A. It
is a simple point. No surprise, if you think of it; git, after all, uses the
same, usual, very simple model everywhere: a key/value database to store the
data, and a key as pointer between one element and the other.
Ok. Now commit
git commit -m "Commit B, my second commit"
With the commit operation you’re saying to git “Ok, take the present ``index`` and make it become your new ``commit``. Then give me back the ``index`` so that I can make a new change”
After the commit in git’s database you will have
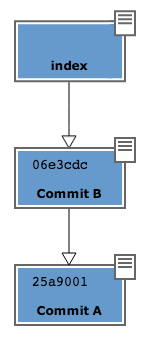
A short remark: git’s graphic interfaces often omit to visualize
index. gitk, for instance, shows it only if there are changes
to be committed. Your repository in gitk is now visualized this
way

See by yourself. Type
gitk
Recapping:
- git always memorizes files in full
- the
commitis one of the several objects stored into git’s key/value database. It’s a container of many pointers to other objects in the database: thetrees, that represent directories, that in turn point to othertrees(sub-directory) or toblobs(files’ content) - every
commitobject has a pointer to its fathercommit, from which it comes - The
indexis a support space where you can build, with differentgit add, the newcommit - with
git commityou record the presentindexmaking it become the newcommit.
Ok: now you have all the theory needed to understand git’s most abstruse
concepts, like rebase, cherrypick, octopus-merge,
interactive rebase, revert and reset.
Let’s go to practice.
