Target 7: designing the ideal workflow¶
If you have used CVS and SVN you will surely be used to the concept of central
repository: every developer makes reference to a single central structure,
where the source code is stored.
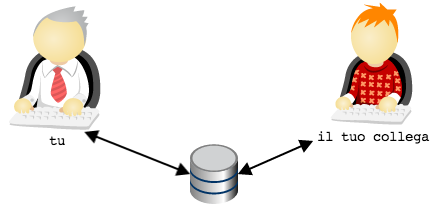
In the example we have used so far the team was made of 2 developers:
your colleague and you. You will have realized that organization
of repositories with git has something particular even with so
small a team: first af all because there are two
repositories; and then because, among the two repositories, one doesn’t
understand which is the official one.
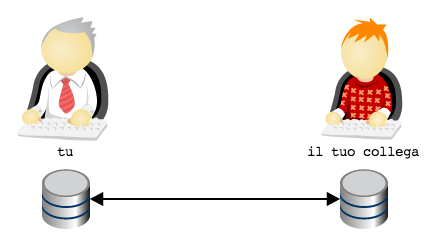
To make things more complicated there’s the fact that, apparently,
one should not allow others to access his own repository. The matter
is definetely confused and hazy.
Let’s try to make it clear. Let’s start with an assumption: git is versatile
enough to totally replicate SVN’s central organization of repositories
Therefore, in case for you it’s an unsustainable cultural shock just thinking of organizing
your workflow in a different way, copy SVN’s structure and you can live happy. You would join
the lengthy list of companies and teams that, in front of the possibilities offered by git, decide
to shelter in the well known architecture based upon the central repository .
That’s one option. Not one of the best, because it prevents enjoying some of the great advantages that come by using a distributed versioning system, but it’s however a viable option. A colleague of mine describes it like “finally having the gun and using it like a club”. Let’s say that it’s not the option that this guide is going to promote.
In this chapter we’ll rather try to explore other less trivial implementations.
Let’s start with a heuristic that I have always found very effective:
use arepositoriestopology reflecting the real workflow and the real functional roles that exist in the team
Translated in a nutshell and applied to our concrete case: you and your colleague are using git mainly for 3 functions
- you, for code development
- your colleague, for code development
- both, to exchange the code and to integrate the work of the two of you
The idea is: for every function use a dedicated repository . In other
words, you might consider the hypothesis of adding one
repository, reachable both from you and your colleague, to be used
as integration area
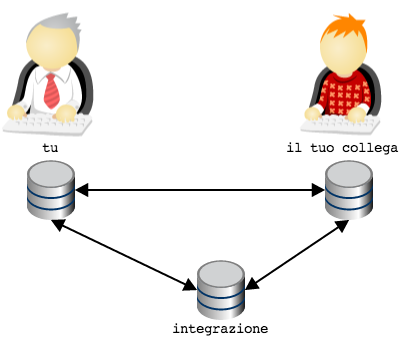
Now it would appear more spontaneous electing the integration
repository as the official one. Don’t you agree?
Strictly speaking, There’s phisically nothing characterizing the
integration repository like central repository : technically it’s totally
equivalent to the other two. The basic idea is that role and importance
of one repository compared with another is a social and organizative
question, not forced by technological costraints or limits:
git merely permits to model it , but it doesn’t impose anything on this aspect.
Then, let’s suppose that, by convention o by agreement between the parts,
we decide that the repository integration is used to allow
the integration between your work and your colleague’s one and as
official archive; the other two repositories will be meant as
archives at the exclusive usage of each developer.
You can strengthen this structure using a couple of tools offered by git.
First of all, you might create the integration repository with the command
git init --bare; the --bare option makes sure that the
repository cannot be used as work base: only the database will be created,
without file system, therefore it’ll be not possible doing add and checkout
Instead, on the two personal repositories , you could carefully configure
the access rights, limiting them only to owners; you will be the only one who
may read and write on your personal repository, and for you it’ll be
impossible to access your colleague’s one; and vice versa. You lose the
possibility to deliver branches each other without passing by
the central repository , but very soon we will see more articulated
configurations.
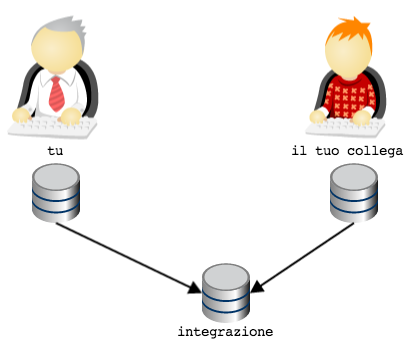
Here it is: you have a topology very similar to SVN’s centralized solution,
with the only difference that each developer has a local private
repository .
Can we do more? Course yes. If it’s worth it. In particular: if the entire development team is made of you and your colleague, this solution could already be perfect.
But things might be very different: for instance consider the case
where your colleague is an external consultant, to whom you
don’t want to give the possibility to change directly code on the official
repository if not after your code revision and acceptance.
One possibility could be deciding that your
repository is the official one, so that Continuous
Integration and Deployment tools can be set up to take the code from there.
Or, you could think back to the heuristic
use arepositoriestopology reflecting the real workflow and the real functional roles that exist in the team
and decide to add a new repository with role of
official archive of code ready to go on production, and limit the write right
only to you
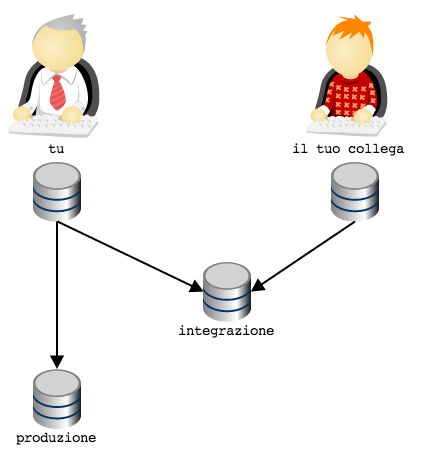
Can you start to guess that this repositories story offers a nearly
unlimited range of possibilities?
Look: I want to show you a topological configuration that is very spread and that for sure you will encounter, especially if you take part in some open source project on GitHub.
Consider again the last image. Your repository and your colleague’s
one are very likely local repositories, hosted on their respective
development systems. Generally, hence, they are not repositories
easily reachable from outside. Therefore, when I drawed the scheme
I had been very superficial and hasty, because I had completely overflown
on the far from trivial problem, of how to arrange so that the two repositories,
maybe hosted on two laptop, without fixed IP or domain, can communicate:
a folders sharing with Samba? A ssh server installed on both laptops? Dropbox?
One of most successful solutions seems suggested by a David Wheeler’s aphorism, that says
All problems in computer science can be solved by another level of indirection
In git might be valid such a law: when you have a workflow problem, try to model
your repositories topology, adding a new level of indirection.
Applied to our case, we might think of delivering to you and
your colleague not one single repository each, but a couple of
repositories: one for private use, to support the development activities,
and a public one, to allow mutual communication
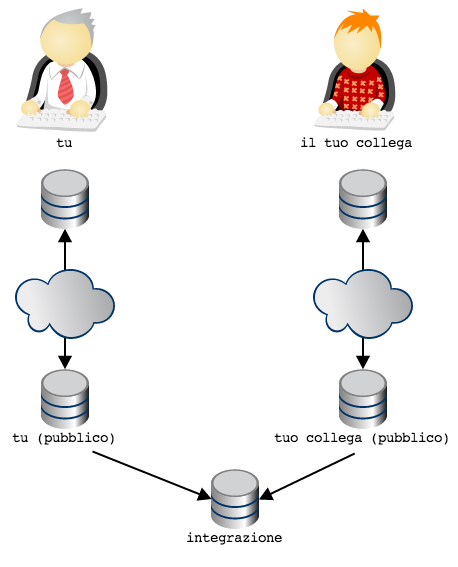
Then: each developer has its own private repository of work, and one
public repository . Everyone may access everyone else’s public
repository, but only the legitimate owner has right for writing
(in the diagram, for simplicity, it’s meant that everyone may access
any public repository for reading ).
Here it is: this is the typical organization of a company that has adopted GitHub’s workflow.
Uncountable variations of this basic organization are possible.
For instance: the team could reckon on code going to production
in functionality packages decided by a release manager
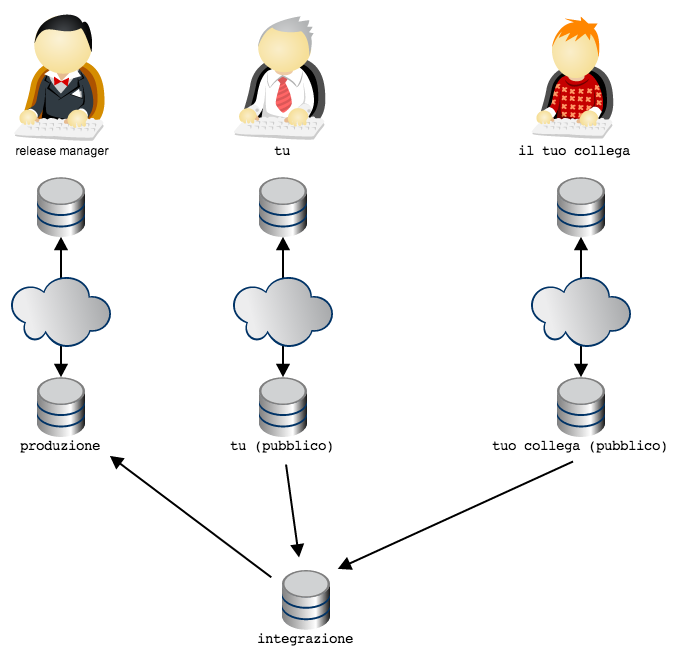
In this topology has been decided that the``repository`` from which
code is taken for deployment to production is the public repository
of the release manager: the release manager takes code from
integration. The workflow is granted by the fact that
release manager is the only one to have push rights on its
own public repository .
Let’s take another example: it might be decided that the product has always to pass by a stage environment (for instance, a production area only for users enabled to beta testing)
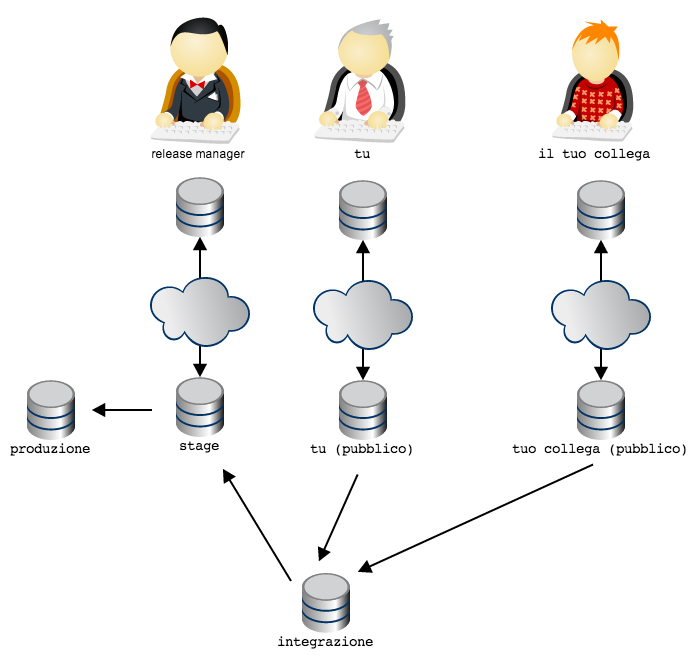
Note how the organization, in git, is obtained not limiting reads
(substantially, in all these diagrams everyone has read rights in every public
repository ), but granting write rights on repositories only to designated owners;
it’ll be then the social convention to state to which usage has every
repository to be devoted (for instance, linking deployment scripts to one
repository rather than another).
The repositories topology could be imagined as a system of
communicating tubs; in every tub the code from one or more other connected tubs
may be selectively made flow; to each person covering a certain
role in the workflow is given the exclusive control of the sluice-gate that
opens or closes the code flow in his tub.
Generally: all workflow kinds that before, with SVN, it was necessary
to implement using naming and branches use convention, in git may be
very easily modelled with repositories topologies. It’s a real pity
when one team that adopted git tries to reproduce a workflow control with the
same systems of SVN, because it’s going to do a great effort and obtain much
less than git could offer.
Instead you will realize that almost always
modelling the repositories net in such a way that it reflects the
workflow and the hierarchic organization of your team is convenient.
For instance, it’s not rare that in big organizations the workflow
is articulated enough to require more teams, with a hierarchic distribution
of roles and responsibilities: there might be a project leader to whom
a couple of team leaders are reporting and that, in turn, manage more persons.
It’s common that in these occasions one tends to model the repositories
net in the image of the roles hierarchy, adopting the so called
“Dictator and Lieutenants
Workflow”
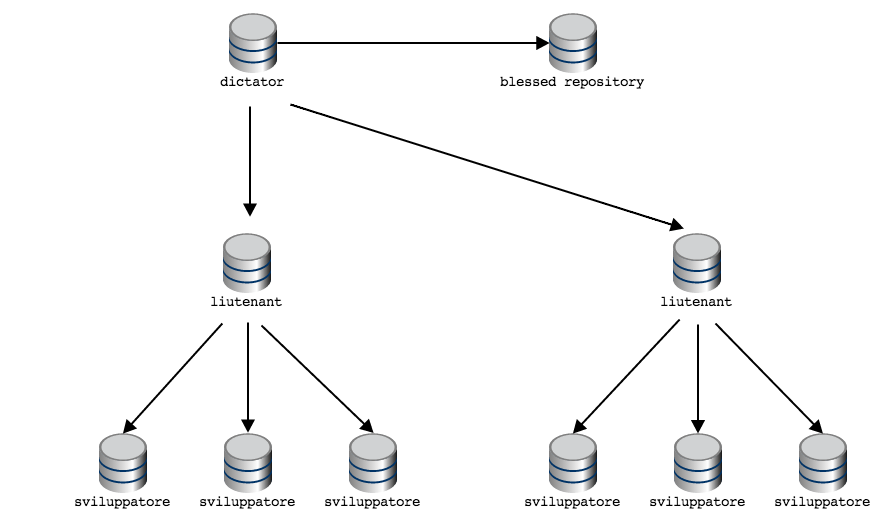
Note that when topologies diagrams are particularly articulated, only public
repositories are shown, taking for granted that each person having control
on that public repository``(that is, having ``push rights) will have
a private``repository`` on its own local machine.
