Target 4: juggling with commit¶
As you have seen, git succeeds in storing the history of all file changes without saving differences. At the beginning of this guide I had anticipated that SVN and git showed an opposite behaviour on this point:
- SVN stores deltas and, when required, rebuilds the present state;
- git stores the present state and, when required, computes deltas.
Therefore, when you look at the repository

and make reference to the dev commit, you mean “the whole project,
as it was photographed at the moment of that commit”.
If you had the same situation on SVN, you would say that the dev commit
“contains all changes applied to files, starting from the immediately
preceding commit”.
git computes the changes applied to files from one commit to another without
difficulty. For instance, you may get them with
git diff dev master
With git diff from to you’re asking git “what is the list of changes
to files that I have to apply to ``from`` so that the project becomes
identical to that one photographed in ``to``”?
With some imagination you can think that lines between commits represent
changes that you applied to files and directories to obtain a commit.
For instance, here in red I put in evidence the line that represents what
you did when you started from B and created the commit pointed by dev.

If you remember, you had done
touch style.css
git add style.css
git commit -m "Now I have also css"
Then you might say that the red line stays for the addition of file
style.css.
Ok. Keep in mind this model. Now I’ll show you one of the craziest and
most versatile git’s commands: cherry-pick.
The Swiss Army knife: cherry-pick¶
cherry-pick applies the changes introduced by one commit in a
different point of the repository.
Let’s see it straightaway with an example. Starting from dev create a branch
named experiment and add a commit
git checkout dev
git branch experiment
git checkout experiment
touch experiment
git add experiment
git commit -m "one commit with an experiment"
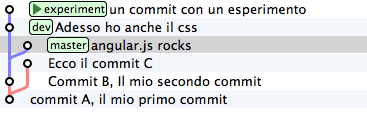
Well: now take into account the change you have just applied starting from
the last dev’s commit and suppose you’re interested in applying the same
change to the master branch as well. With the command cherry-pick you may ask
git to compute the changes introduced by your commit and apply them again
somewhere else , for instance exactly on master
git checkout master
git cherry-pick experiment

cherry-pick “gets” the commit you indicate and applies it on
the commit where you are.
Do you begin to sense how it’ll be possible for you to juggle with this tool? I want to give you some cue.
Correcting a bug in the middle of a branch¶
Starting from master create a branch feature and add 3
commits to it
git checkout -b feature # shortcut to do branch + checkout
touch feature && git add feature
git commit -m "feature"
touch horrible-bug && git add horrible-bug
git commit -m "horror and revulsion"
touch other-feature && git add other-feature
git commit -m "other feature"
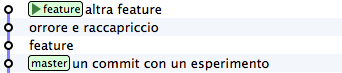
Oh, no! The second commit, that one with the comment “horror and
revulsion” has been a huge mistake! Ah, could we only rewrite the story
and remove it!
You can do it! The idea is to bring feature back in time, on
master, and to use cherry-pick to apply changes again one by one,
careful not to apply changes introduced by
“horror and revulsion”. You only need to know the values of the
keys of the 3 commits
git log master..feature --oneline
8f41bb8 other feature
ec0e615 horror and revulsion
b5041f3 feature
(master..feature is a sintax that allows to express a range
of commits: we’ll speak of it later on)
It is time to go back in time. Take place on master again
git checkout master
and move feature on it, in such a way that it goes back to the position
where it was when you created it before commits
git branch --force feature
git checkout feature
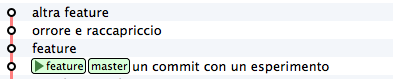
Perfect. You didn’t revive exactly the past repository,
because your new 3 commits are still there, but branches have
been positioned where they were beforehand. You just have to take, with
cherry-pick, the only commits you’re interested in. Take the first one,
with the feature comment
git cherry-pick b5041f3
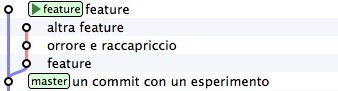
Can you see? The commit has been added to feature, that moved foreward afterwards.
Go on with the second commit, skipping the incriminated commit
git cherry-pick 8f41bb8
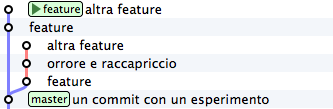
Et voilà. You have rebuilt the development branch skipping the wrong commit.
It remains an orphan branch, that is, with no branch: it’ll be
removed sooner or later by the git’s garbage collector. Moreover, usually
orphan branches are not shown by graphical editors, therefore, normally, you
should see as starting situation the following one:
and this one as final situation:

Wow! You have the impression that git rewrote the history canceling
one commit in the middle of a branch, don’t you?
In fact, many people say that git is able to rewrite the history, and that
this behaviour is extremely dangerous. It should be a little clearer that it’s
not exactly like this; git is extremely conservative and when it allows you to manipulate
commits, it does nothing but act in append, building new branches,
never removing what exists already.
Note also another thing: at the moment when you rebuilt the branch
bringing with cherry-pick one commit at a time, nothing was
obliging you to apply again the commits in the same original order:
if desired, you could have applied them conversely, obtaining, in fact, a
branch with the commit in reverse order. It’s not something that often
happens to need, but now you know that it’s possible.
Moving a development branch¶
I want you to see another magic of cherry-pick, in order to introduce
the rebase command.
Resume your``repository``.
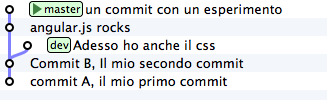
Let’s say you want to carry on the development of your css, therefore
you’ll do a new commit on dev
git checkout dev
echo "a { color:red; }" >> style.css
git commit -am "links are red"
Note: I have used the -a option of commit, that implicitly executes
git add of any changed file. Keep in mind this option:
it’s very handy and very often you will find yourself using it.
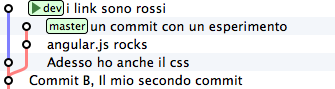
Very good. Your css are ready to go to production. It’s just a pity
that the dev tree lagged a little compared to master,
that you might decide to account as the production-ready code.
After all, what could you do? While you were dealing with css, master
went ahead and dev, obviously, remained there where you created it.
It would be wonderful if we could detach the dev branch and move it on
master…
Don’t you rememeber cherry-pick? It’s a case like the previous one:
but instead of travelling in the past you have to have a bit of fantasy
and to imagine to travel in the future. It would be about bringing
the two dev’s commits one by one and applying them again on last
master’s commit (that, re dev, is the future).
That is: using cherry-pick you could rewrite the history as if
dev’s commits had been written after
master’s commits.
If you did it, this would be the result

Compare it with the initial situation
You could interpret it this way: the dev branch has been detached and implanted on master.
Here: rebase is nothing else than a macro that authomatically executes
a set of cherry-pick, in order to avoid you to move one
commit at a time from one branch to the other.
Try it. On your repository
run
git rebase master
Voilà!
You asked git: “move current branch on new ``master`` base”.
Remember: rebase is entirely equivalent to moving
commits with ``cherry-pick``one by one. It’s just more comfortable.
Can you imagine where might rebase be useful for you? Look,
I try to describe a very common situation.
Start detaching a new branch from dev and registering 3 new
commits
git checkout -b sviluppo
touch file1 && git add file1 && git commit -m "step 1"
touch file2 && git add file2 && git commit -m "step 2"
touch file3 && git add file3 && git commit -m "step 3"
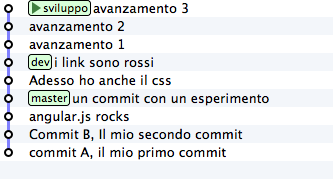
Well. Now let’s simulate one thing that happens very often in real world:
your colleagues, while you were working on your 3 commits made the
dev branch advance with their contributions
git checkout dev
touch dev1 && git add dev1 && git commit -m "developer 1"
touch dev2 && git add dev2 && git commit -m "developer 2"

This situation is basically unavoidable, because of the strongly non linear
nature of the development process: it’s a direct daughter of the fact that
people work in parallel. rebase allows you to make the history of the
repository linear again. as in the previous example, your development branch
remained behind re dev’s evolutions: use rebase in order to detach it
from his base and attach it later on
git checkout development
git rebase dev
With git rebase dev you are asking git “apply again all the work
I did in my ``branch`` as if I had detached from last ``development`` ``commit``,
but don’t force me to move ``commits`` one by one with
cherry-pick”
The result is
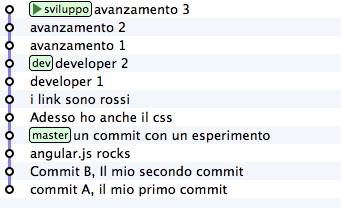
Do you see? Last 3 commits introduce the same identical changes
that you made in your branch, but everything appears as if you had
detached the branch from last dev version. Again:
apparently you rewrote the history.
When you will get used to git you will discover that you can use
cherry-pick (and other commands, that often are a sort of combination
of lower level commands) to manipulate your
commits and obtain results that are literally impossible
with other versioning systems:
- inverting the order of a set of
commits - breaking in two splitted branches a single code line
- exchanging
commitsbetween one branch and the other - adding a
commitwith a bugfix in the middle of abranch - splitting a
commitin two parts
and so on.
This versatility shouldn’t amaze us that much: in the end git is nothing different than a key/value database and its commands are nothing different than macros to create objects and to apply to them the arithmetic of pointers.
Therefore, everything can come in your mind to do with objects and pointers, tendentially you can do it with git
Cute, isn’t it?
